
ICCV 2025 | FDAM:告别模糊视界,源自电路理论的即插即用方法让视觉Transformer重获高清细节

针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。
该工作来自北京理工大学、RIKEN AIP和东京大学的研究团队。

- 论文全文: https://arxiv.org/abs/2507.12006
- 作者主页: https://linwei-chen.github.io
- 实验室主页: https://ying-fu.github.io
- 开源代码: https://github.com/Linwei-Chen/FDAM
研究背景:为什么这是一个重要的问题?
视觉 Transformer(ViT)无疑是近年来计算机视觉领域最耀眼的明星。它凭借强大的全局建模能力,在图像分类、目标检测、语义分割等众多任务上刷新了纪录。然而,当我们构建更深、更强大的 ViT 模型时,一个 “隐秘的角落” 里的问题逐渐浮出水面:模型看世界,怎么越来越模糊了?
这并非错觉。对于分割、检测这类需要精确定位的 “密集预测” 任务而言,图像的边缘、纹理等高频细节至关重要。但研究发现,ViT 中的核心部件 —— 自注意力机制(Self-Attention),其本质上像一个低通滤波器。这意味着每经过一层注意力,图像特征中的高频细节就会被削弱一分,而平滑的低频结构则被保留和增强。当我们将数十个这样的 “滤波器” 堆叠起来,灾难性的 “频率消失”(Frequency Vanishing)现象便发生了:网络深层的特征几乎完全丢失了细节信息,导致表征坍塌(Representation Collapse),最终输出的预测结果自然也就模糊不清、边界不准。
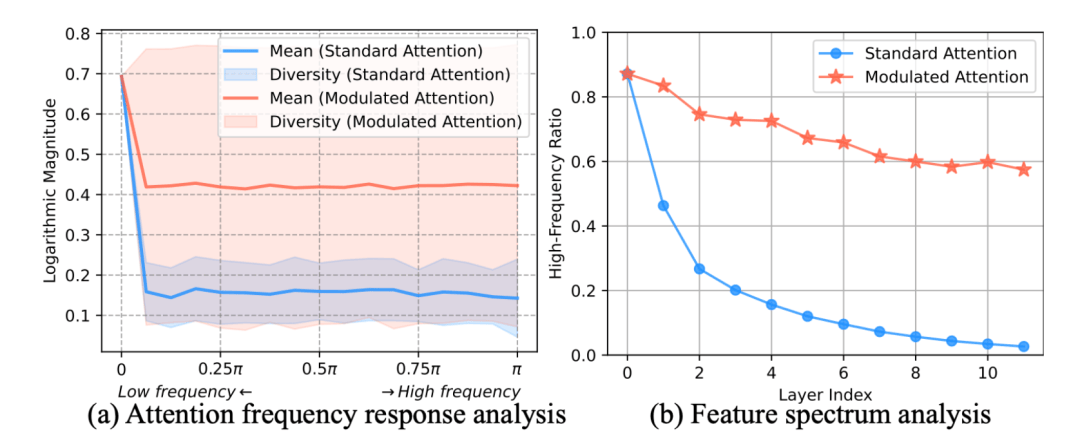
正如上图所示,在标准的 ViT 中,高频信息随着层数加深迅速衰减至零。解决这一根本性缺陷,释放 ViT 在高清视觉任务上的全部潜力,是当前领域亟待突破的关键瓶颈。
现有方法的局限性
此前,一些工作尝试缓解 ViT 的 “过平滑” 问题,例如通过正则化或直接在频域上对衰减的高频信号进行静态补偿(如 AttnScale, NeuTRENO 等)。这些方法起到了一定作用,但它们更像是 “亡羊补牢”—— 在细节丢失后进行被动修复,而未能从根本上改变注意力机制的低通天性。它们缺乏一种动态、自适应的能力,来根据不同图像内容和任务需求,灵活地处理全频谱的视觉信息。
FDAM 的核心思想是什么?
既然问题出在注意力机制这个 “元件” 上,我们能否重新设计这个 “电路”?我们的核心思想,源于经典的电路理论。
想象一下音响上的均衡器。标准注意力就像一个只有 “重低音”(Low-Pass)的旋钮,它会滤掉清亮的高音。我们如何凭空造出一个 “高音”(High-Pass)旋钮呢?电路理论给了我们一个绝妙的启示:高通滤波器 = 全通滤波器 - 低通滤波器。
这个简单的公式正是我们方法的核心 —— 注意力反转(Attention Inversion, AttInv)。
- “全通滤波器” 是什么?就是未经处理的原始特征,它包含了所有频率的信息。
- “低通滤波器” 是什么?就是标准注意力模块处理后的特征,它只保留了低频成分。
两者相减,得到的 “残差” 不就恰好是那些被滤掉的高频细节么?
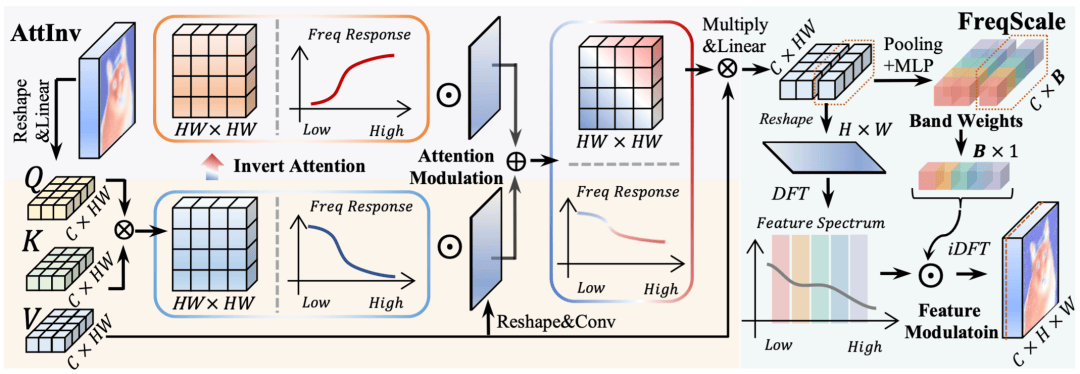
基于此,我们的 AttInv 模块不再是单一的低通滤波器。在每一层,它都同时拥有了原始的 “低通” 路径和我们创造的 “高通” 路径。更关键的是,我们引入了一个轻量级的动态 “混音器”,让模型能够根据图像上每个区域的特点,自主学习是该更关注平滑的整体结构(低频),还是更聚焦于锐利的边缘纹理(高频)。当这样的模块堆叠起来,模型便拥有了 2^L 种(L 为层数)复杂的频率组合能力,能够拟合出远比之前丰富多样的频率响应。
方法的关键组成部分
当然,仅有 “低音” 和 “高音” 两个旋钮对于专业音响师来说还不够。为了实现更精细的 “调音”,我们设计了第二个关键组件:频率动态缩放(Frequency Dynamic Scaling, FreqScale)。
FreqScale 就像一个多频段图形均衡器。它将特征图转换到频域,将其划分为多个频段,并为每个频段学习一个动态的增益权重。这样,模型不仅能区分高低频,还能根据需要精确地 “增强” 或 “抑制” 某个特定频段的信号,例如,为分割任务特别增强中高频的边缘信号。
FDAM = AttInv (粗调高低频) + FreqScale (精调各频段)。两者结合,构成了一套完整、高效且自适应的全频谱解决方案。
实验效果有多惊艳?
我们的 FDAM 模块是 “即插即用” 的,可以轻松集成到各种主流 ViT 架构中,且带来的参数量和计算量开销微乎其微。但效果的提升却是实实在在的:
定量展示:
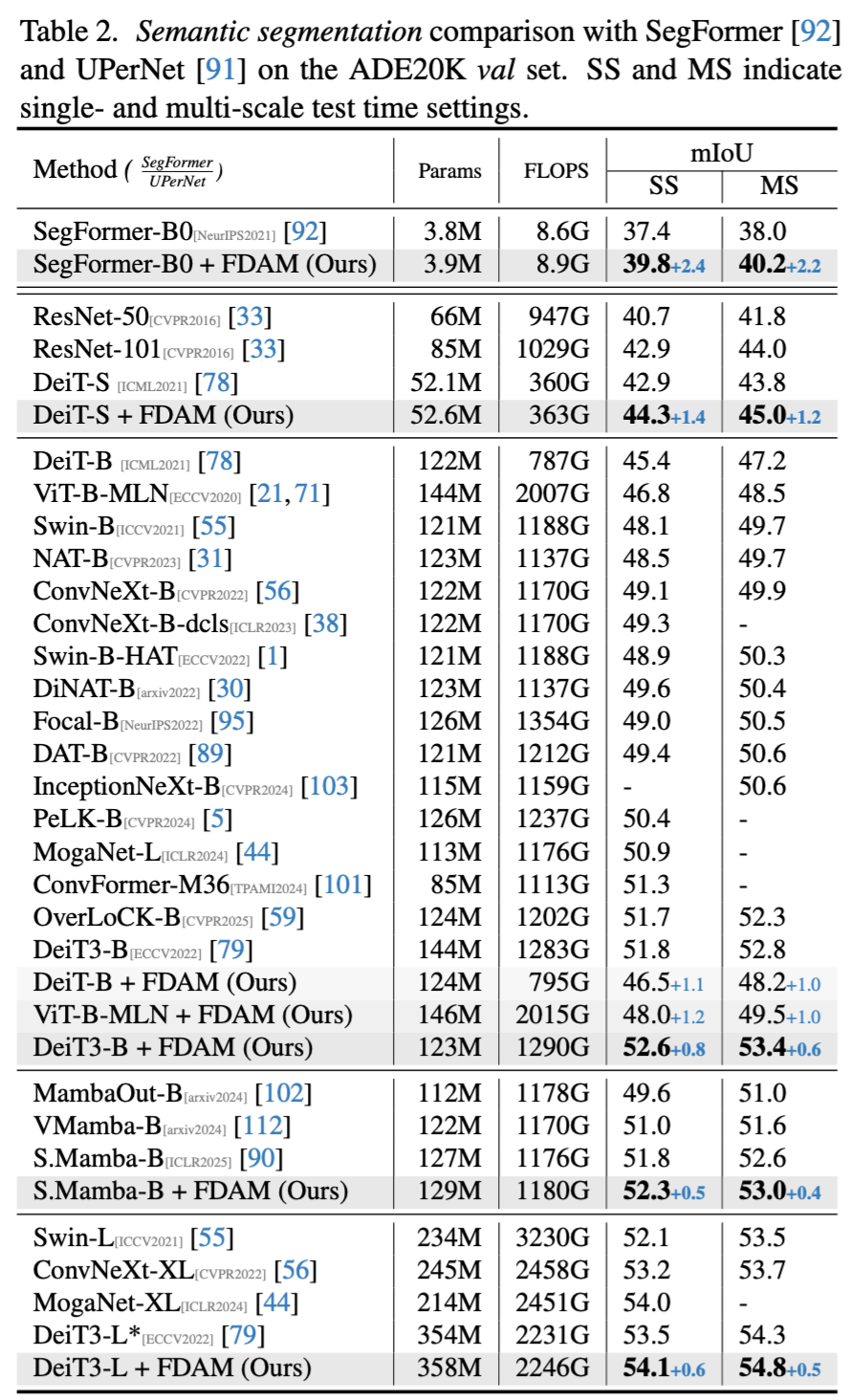
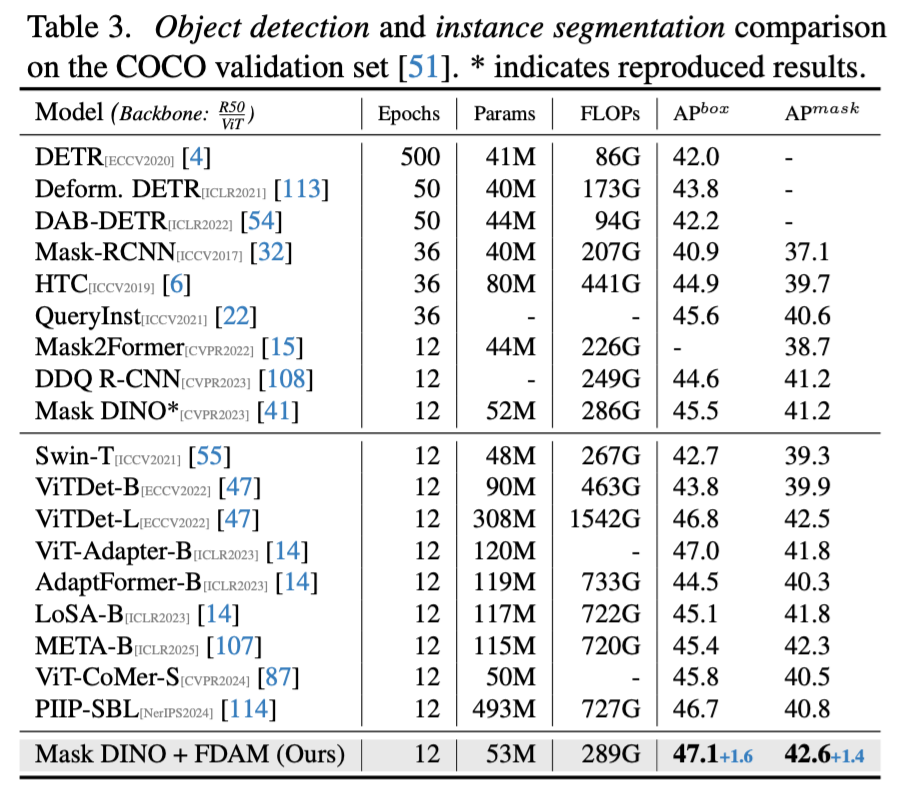
- 在语义分割任务中,FDAM 为轻量的 SegFormer-B0 在 ADE20K 数据集上带来了 +2.4 mIoU 的巨幅提升。对于强大的 DeiT3-Base,FDAM 依然能稳定提升 +0.8 mIoU,达到了 52.6% 的 SOTA 性能。
- 在目标检测与实例分割的 “兵家必争之地” COCO 数据集上,FDAM 赋能 Mask DINO,将检测 AP 提升了 +1.6,分割 AP 提升了 +1.4,效果显著。
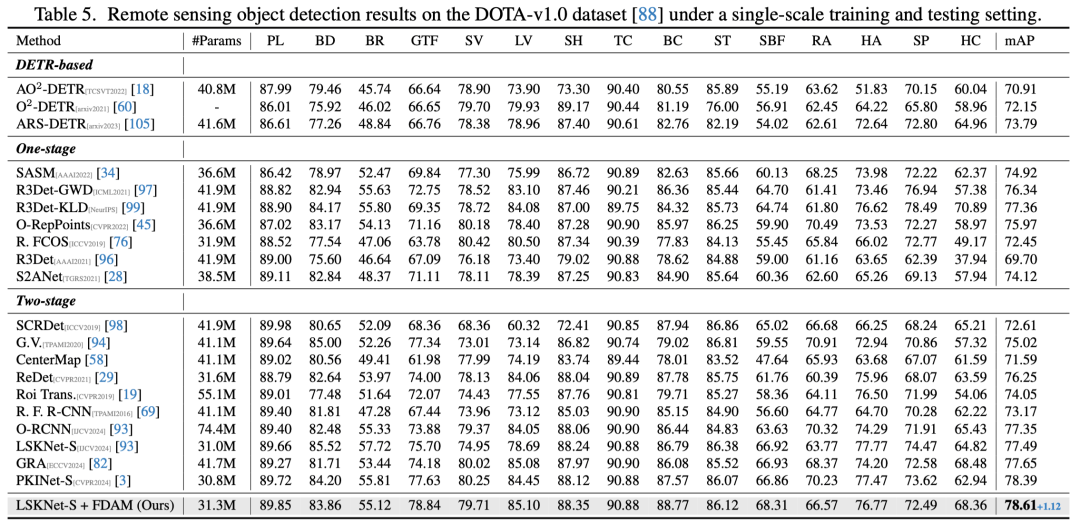
- 在遥感图像检测 DOTA 数据集上,我们的方法同样取得了当前单尺度设定的最优成绩。
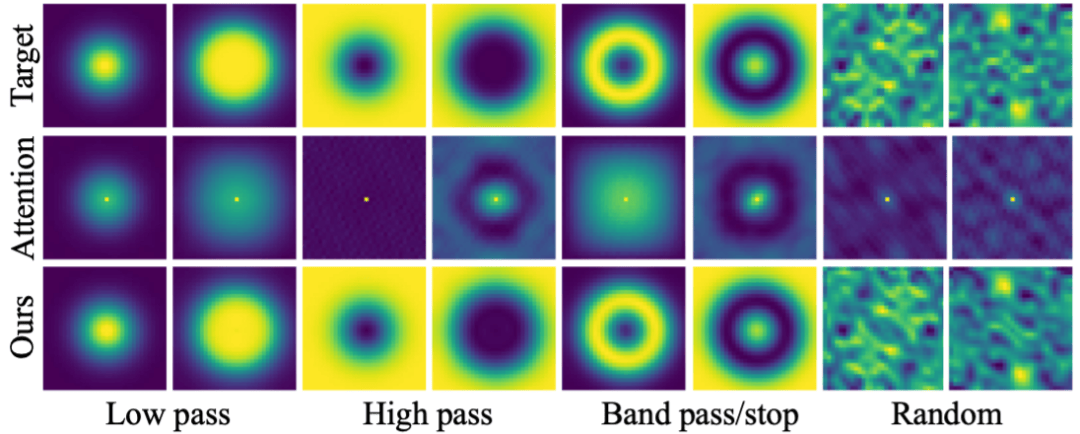
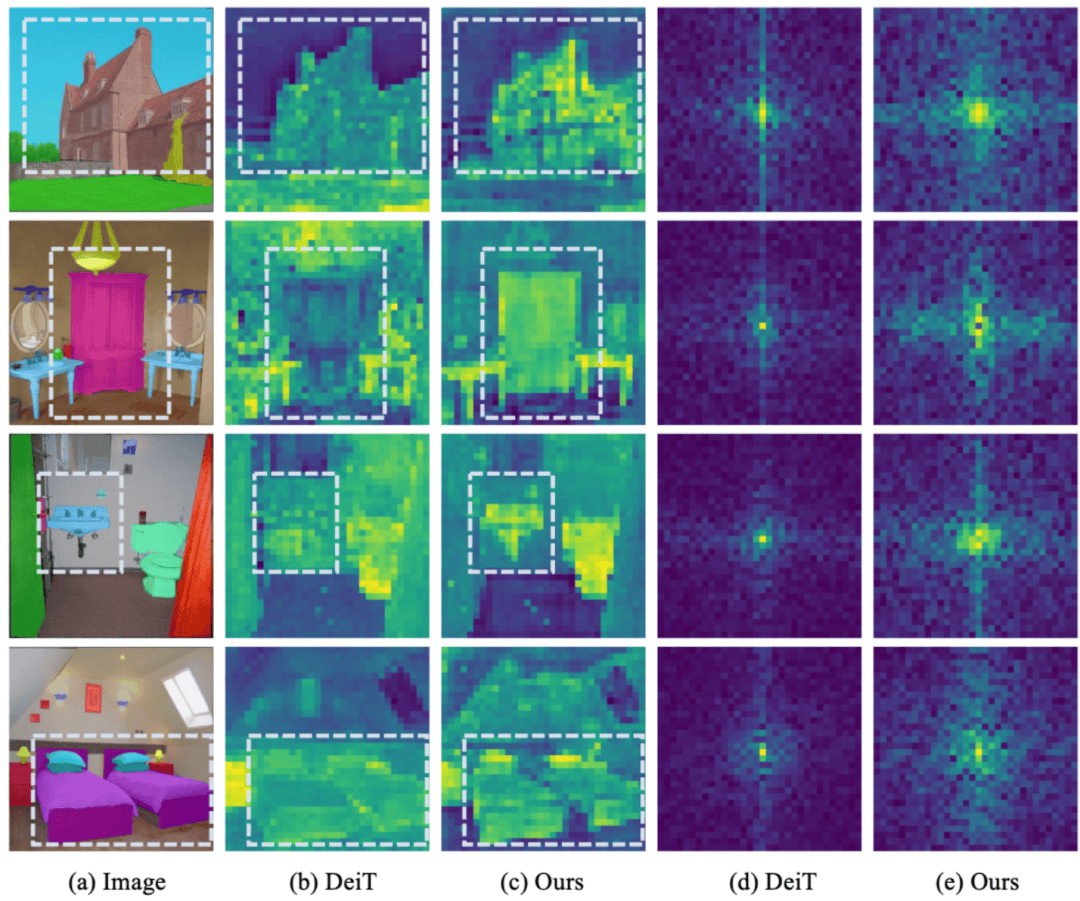
定性展示:
- “一图胜千言”。从下方的特征图对比中可以直观地看到,标准 DeiT 的特征图(b)细节模糊,而经过 FDAM 增强后的特征图(c)轮廓清晰、纹理锐利,物体的结构被完美地保留了下来。其对应的频谱图(e)也证实了我们的方法保留了更丰富的高频成分。
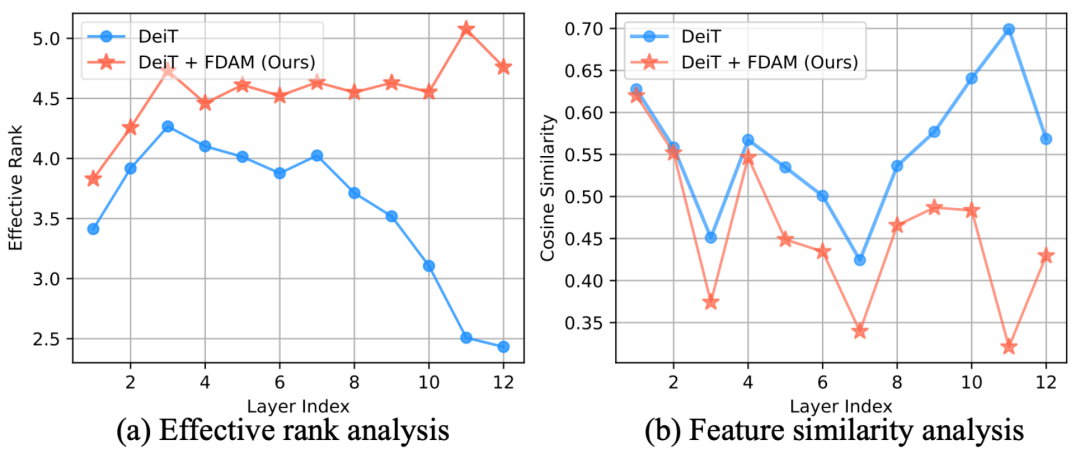
理论支撑:
- 我们的方法不仅效果好,理论上也站得住脚。分析表明,FDAM 能有效抵抗表征坍塌,其 “有效秩”(Effective Rank)在网络深层远高于基线模型,证明了特征的多样性得到了更好的维持。
这项工作意味着什么?
FDAM 的价值不仅在于刷新了几个 SOTA 点数,更在于:
1. 提供了新视角:它成功地将经典的电路理论思想引入到前沿的 Transformer 设计中,为解决深度学习中的基础问题(如信息衰减)提供了一个全新的、符合第一性原理的思考框架。
2. 解决了真问题:它精准地定位并有效解决了 ViT 在密集预测任务中的一个核心痛点 ——“频率消失”,将 ViT 的潜力更充分地释放出来。
3. 兼具实用与优雅:作为一个轻量、即插即用的模块,FDAM 可以毫不费力地为现有模型 “增压”,在工业界和学术界都有着巨大的应用潜力。
这项工作可能会推动社区在需要高清细节的领域(如医学影像分析、高分辨率遥感、自动驾驶感知)中更广泛地应用和探索更深层的 ViT 模型。
未来可以探索的方向
FDAM 也为未来研究打开了新的大门。例如,我们是否可以设计一个完全在频域中进行动态路由的全新网络结构?这种频率调制的思想能否被拓展到视频、三维点云甚至多模态数据中?这些都是激动人心的未来方向。
欢迎在 ICCV 2025 现场与我们交流!
作者介绍:

付莹是北京理工大学计算机学院的教授、博士生导师,入选国家高层次青年人才计划。她的研究领域主要为人工智能、计算机视觉与计算摄像学。近五年,她在中科院一区期刊和 CCF A 类会议上发表了超过 50 篇论文。她的研究成果已应用于 “嫦娥工程”、智慧城市建设等重要项目。她主编的《计算机视觉基础》教材入选北京理工大学 “十四五” 规划教材。她获得的荣誉包括 ICML 杰出论文奖、日内瓦国际发明展金奖,并入选中国图象图形学学会石青云青年女科学家奖和中国电子学会青年科学家奖等。此外,付教授还担任 TIP 等期刊的编委,并担任 CVPR、ICCV 等顶级会议的领域主席。

谷林(Lin Gu)是 RIKEN AIP(理化学研究所)的研究科学家,同时也是东京大学的特别研究员。他的研究重点是通过进化方法开发新一代人工智能,旨在超越人脑的局限性。
谷林先生的研究涵盖了计算机视觉、医学成像、大型语言模型(LLM)、机器人技术甚至核聚变等多个领域。 他在 Nature Methods、PAMI、IJCV、AAAI 等顶级期刊和会议上发表了 60 多篇论文。此外,他还是 Pattern Recognition 期刊的副主编,并担任 ICCV、ICML、NeurIPS 和 ICLR 等多个会议的领域主席。
目前,谷林先生是日本内阁府监督的国家级项目 “Moonshot Program” 的项目经理,并担任 RIKEN-MOST 项目的日本首席研究员(PI),该项目专注于通过人工智能技术对精神分裂症进行亚型分类和早期诊断。

陈林蔚,北京理工大学计算机学院博士。主要研究方向为计算机视觉,重点关注图像分割、目标检测、低光照图像增强与识别以及图像生成等领域。截至目前,他已发表论文十余篇,其中多篇以第一作者身份发表在国际计算机视觉顶级期刊和会议(如 TPAMI、IJCV、CVPR、ICLR、ISPRS)上。在学术社区贡献方面,他担任 IJCV、TIP、CVPR、ICCV、NeurIPS、AAAI 等多个期刊会议的审稿人,并在国际计算机视觉会议 BMVC 中因专业素养和贡献被评为 "杰出审稿人"。