
仅100种子题,合成数据质量超GPT-5,阿里、上交提出Socratic-Zero框架

本文(共同)第一作者为王少博(上交 AI)、焦政博(上财)。(共同)通讯作者为魏虎(阿里巴巴)和张林峰(上交 AI)。本文其他作者来自阿里巴巴、武大、浙大等。
最近一篇来自阿里巴巴和上交等单位的 Agent 自进化工作得到了推特大佬们的关注。首先是 Rohan Paul 的两次转发:


网友对此也高度评价:
让我们看看这篇工作到底是怎么做的?
引言:从 “数据饥渴” 到 “自给自足”
当前大语言模型在数学推理上的突破,高度依赖海量人工标注数据。以 MetaMath 和 WizardMath 为代表的静态增强方法,虽能通过提示工程合成训练样本,但其生成的问题质量不稳定,且无法动态适配模型能力演进,导致训练信号效率低下。
为突破这一瓶颈,阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。

- 论文链接:https://arxiv.org/pdf/2509.24726
- GitHub 地址:https://github.com/Frostlinx/Socratic-Zero
苏格拉底的 “助产术”:从哲学对话到智能体协同
两千多年前,苏格拉底在雅典街头与青年对话,从不直接给出答案,而是通过一连串精准的提问,引导对方暴露认知盲区、修正错误信念,最终 “自己生出” 真知。他称这种方法为 “精神助产术”(maieutics)—— 教师不是知识的灌输者,而是思维的接生者。
这一古老智慧在今天的大模型时代焕发出惊人回响。当现代 AI 面临推理能力瓶颈,传统路径依赖海量标注数据 “喂养” 模型,而苏格拉底却启示我们:真正的智能,或许不在于拥有多少答案,而在于能否通过高质量的提问,激发自我修正与持续进化的能力。
受此启发,阿里巴巴与上海交通大学 EPIC Lab 将这一哲学理念转化为可计算的协同机制,提出 Socratic-Zero—— 一个由 Solver(学生)、Teacher(导师)与 Generator(学徒)构成的三智能体自进化系统。在这里,没有外部数据的 “喂养”,只有智能体之间的 “诘问” 与 “反思”;没有静态课程的灌输,只有动态生成的挑战与反馈。正如苏格拉底所言:“我不能教人任何东西,只能让他们思考。” Socratic-Zero 正是在这一精神下,让大模型学会 “自己教自己推理”。
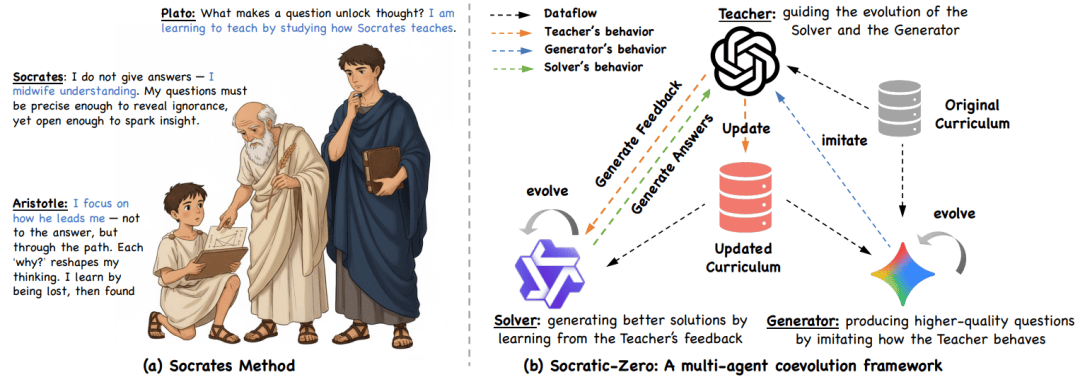
论文 Figure 1 (a) 苏格拉底教学法展现的哲学根基:导师(苏格拉底)如同思想助产士,通过探询式提问引导理解;实践者(亚里士多德)并非被动接受答案,而是循着理性探究之路获得启迪;学徒导师(柏拉图)则通过观察并内化大师的方法来习得教学之道。(b) Socratic-Zero 框架将这一理念付诸实践。在此框架中,教师 —— 一个强大的法律语言模型 —— 引导两个智能体的协同进化。解题器通过生成解决方案并借助教师反馈进行优化而不断改进,生成器则通过策略性地提炼教师行为来进化,从而为解题器生成日益适配的课程体系。
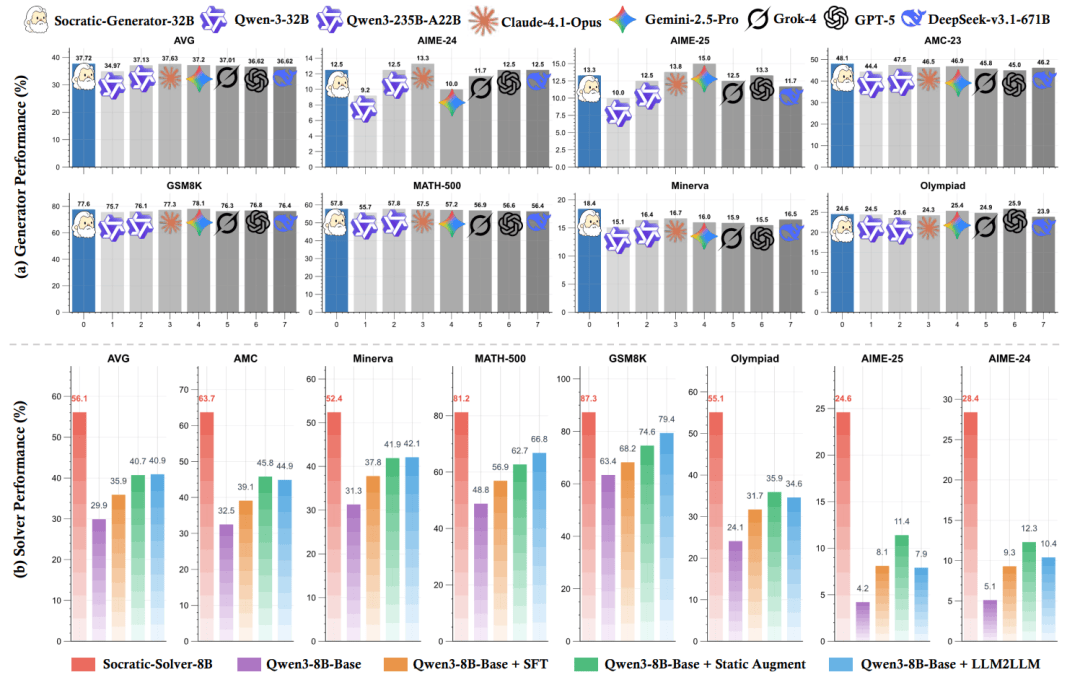
核心突破:在极简启动条件下,合成数据质量全面超越 GPT-5、Gemini-2.5-Pro、Claude-4.1-Opus 等顶级闭源模型作为数据生成器时的表现。
方法详解:三智能体 “苏格拉底铁三角”
Socratic-Zero 的核心是一个受苏格拉底 “助产术” 启发的多智能体系统,包含三个角色:
- Solver(学生):尝试解答问题,并通过偏好学习(DPO)从成功与失败轨迹中自我修正;
- Teacher(导师):基于 Solver 的错误,动态生成更具针对性的新问题,精准暴露其知识盲区;
- Generator(学徒):模仿 Teacher 的出题策略,通过价值加权监督微调(WSFT)蒸馏其 “教学智慧”,实现课程的规模化生成。
三者构成一个闭环自进化系统:Solver 的弱点驱动 Teacher 出题,Teacher 的行为被 Generator 学习,Generator 产出的新问题又反哺 Solver 训练 —— 全程无需人类干预。
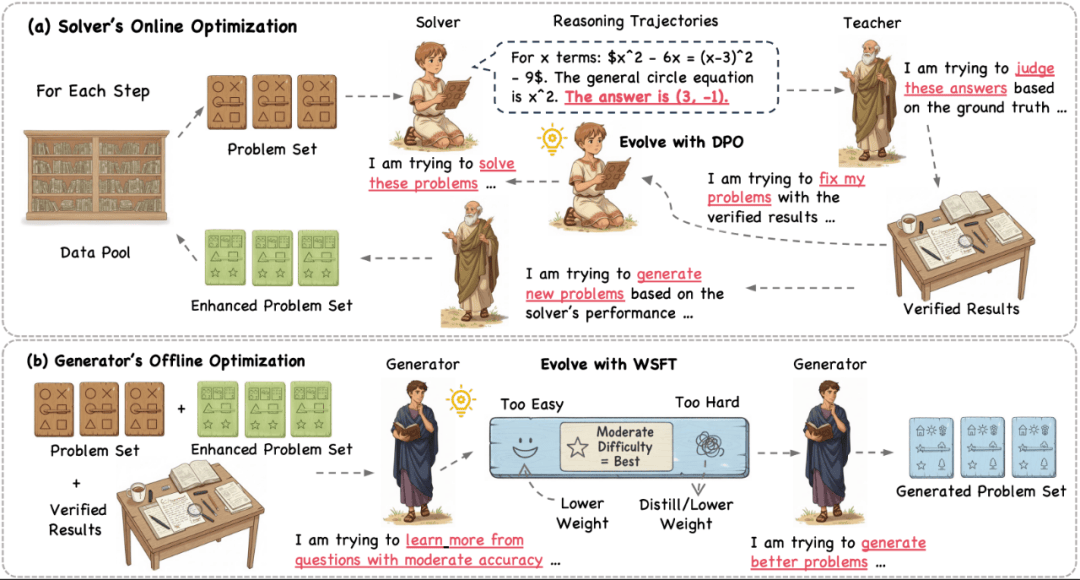
1. Solver 的在线偏好优化(Online DPO)
Solver 在当前课程上对每个问题生成 ( k=8 ) 条推理轨迹。Teacher 的验证函数判断每条轨迹是否正确,从而构建偏好对:正确轨迹为 “胜”,错误轨迹为 “负”。
若 Solver 全部失败,则使用课程中的参考答案作为唯一 “胜” 样本,确保偏好信号始终存在。Solver 通过 Direct Preference Optimization (DPO) 更新策略。若 Solver 全部失败,则使用课程中的参考答案作为唯一 “胜” 样本,确保偏好信号始终存在。
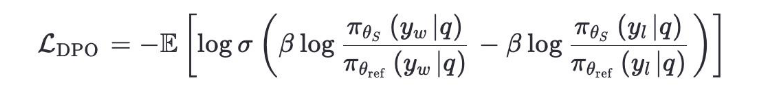
2. Teacher 的自适应出题机制
Teacher 是一个固定的大模型(Qwen3-235B-A22B),具备两个确定性函数:
- 验证函数:判断解法是否正确;
- 问题精炼函数:基于 Solver 的错误解法,生成一个新问题及其参考答案。
新问题的设计原则是:保留原问题的数学本质,但针对性修复 Solver 的推理漏洞。
关键保障机制:当 Solver 对某问题全错时,Teacher 会启动 Self-Verification Protocol—— 重新求解该问题,验证参考答案是否正确,防止低质量问题污染课程
3. Generator 的价值加权蒸馏(WSFT)
为避免持续调用昂贵的 Teacher,Generator 通过 Weighted Supervised Fine-Tuning (WSFT) 学习其出题策略。关键创新在于引入价值函数:

4. 为何仅需 100 个种子?
论文 Appendix F 详细说明了种子选择协议:
- 难度对齐:种子来自 MATH 数据集 Level 2–4,确保 Solver 初始成功率 50% 上下,避免 “太易” 或 “全错”;
- 领域覆盖:100 个问题均匀分布于代数、数论、几何、组合等 7 个数学子领域;
- 多样性保障:通过嵌入聚类确保解法路径多样,避免同质化;
- 质量控制:所有种子经 Teacher 多次验证,排除歧义或错误问题。
这一精心设计的启动集,为后续自进化提供了高质量、高信息量的 “引信”。
实验结果:极简启动,极致性能
1. Solver 性能:+20.2 个百分点提升
在 7 个数学推理基准(AMC23、AIME24/25、Olympiad、MATH-500、Minerva、GSM8K)上,Socratic-Solver-8B(基于 Qwen3-8B)平均准确率达 56.1%,相比 MetaMath 和 WizardMath(平均 40.7%),绝对提升 +15.4 个百分点;相比 LLM2LLM 提升 +15.2 个百分点。
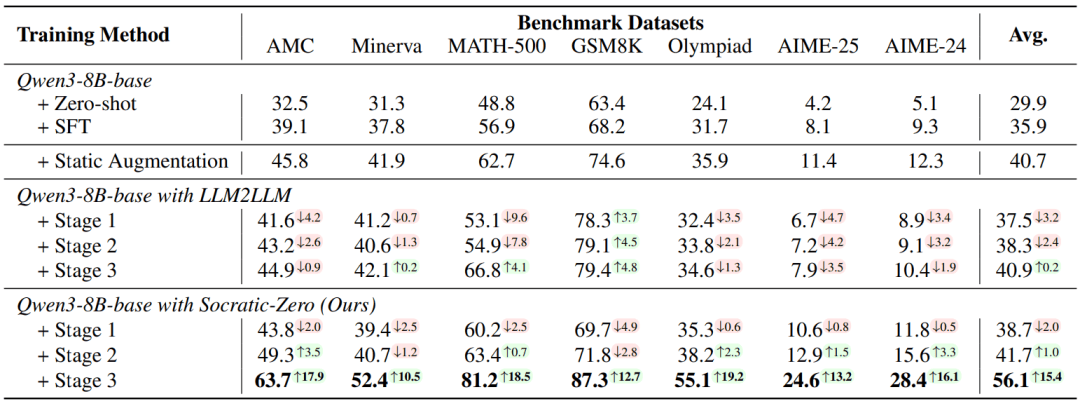
在高难度竞赛题上优势更显著:
- AIME-24:28.4% vs. 12.3%(+16.1)
- Olympiad:55.1% vs. 35.9%(+19.2)
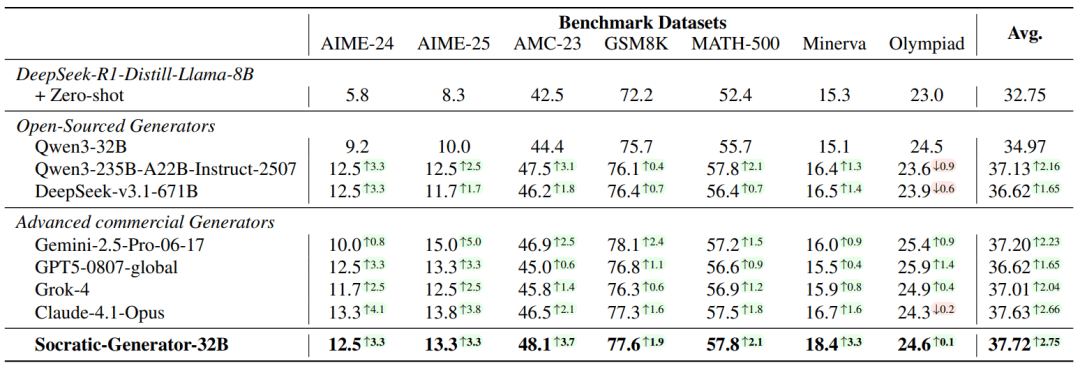
2. Generator 质量:合成数据超越闭源大模型
研究团队用各模型生成 3,000 道数学题,微调 DeepSeek-R1-Distill-Llama-8B 作为学生模型,测试其下游性能:
关键结论:仅用 100 个种子问题启动的 Socratic-Generator-32B,其合成数据质量已超越 GPT-5、Gemini-2.5-Pro 等闭源大模型作为数据生成器时的表现。
此外,Socratic-Generator-32B 的问题有效性达 95.6%,接近 GPT-5(95.8%),远超其基座模型 Qwen3-32B(89.1%)。
工程价值:轻量、可复现、高性价比
Socratic-Zero 的训练流程高度工程友好:
- 硬件:Solver 训练仅需 8×NVIDIA H20 GPU,Teacher 推理使用 16×AMD MI308X;
- 评估可靠性:采用 MathRule(规则提取) + LLM Judge(语义验证) 双验证机制,确保结果可信;
- 可迁移性:框架设计通用,可扩展至代码等其他推理领域。
结语
Socratic-Zero 证明:在推理能力构建中,高质量的教学策略可能比模型规模更重要。一个仅用 100 个种子问题启动的 32B Generator,竟能产出优于 GPT-5 的训练数据 —— 这为资源受限的团队提供了新的可能性。
更重要的是,它开启了一条零数据、自进化的新路径:无需人类标注,仅靠智能体之间的协同演化,就能实现推理能力的螺旋式上升。
欢迎社区开发者与研究者试用、拓展,共同探索智能体协同进化的边界。