
医疗AI迎来大考!南洋理工发布首个LLM电子病历处理评测 | AAAI'26

新智元报道
编辑:LRST
【新智元导读】南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。基于此,团队提出EHRMaster框架,与Gemini联合后性能超越现有模型。
电子病历(EHR)是医疗体系中最核心的数据形态,集中呈现患者在诊断、检验、用药、生命体征监测与疾病管理过程中的关键临床信息,是临床决策的重要基础。
随着LLM逐步应用于医疗场景,如何使其有效理解和处理这些结构化的EHR,从而辅助医生完成关键的数据分析与临床推理,已成为推动医疗人工智能发展的重要问题。
因此,南洋理工大学的研究人员提出了首个全面评测LLM处理结构化电子病历能力的综合基准EHRStruct,由计算机科学家与医学专家共同构建,并按照临床场景、认知层级与功能类别进行层次化组织,全面的覆盖了LLM处理结构化EHR的11项核心任务,包含2,200个标准化样本,为医疗大模型的可控性、可靠性与临床可用性提供统一而严谨的可解释评测框架。
论文链接:https://arxiv.org/abs/2511.08206
代码开源:https://github.com/YXNTU/EHRStruct
基于EHRStruct,研究团队对20个主流LLMs与11种先进的增强方法进行了全面的评测,并在此基础上提出了一种代码增强框架EHRMaster。
EHRMaster与Gemini联合,使LLM处理结构EHR的性能全面超越SOTA模型。研究成果已被AAAI 2026 Main Technical Track录取为Oral论文。
同时发布的还有EHRStruct 2026 - LLM结构化电子病历挑战赛(EHRStruct 2026 - LLM Structured EHR Challenge),旨在为研究者提供一个统一、严谨且可对比的LLM处理结构化EHR能力的评测平台,可直接作为论文实验结果的标准基准。
研究人员也将与国际会议洽谈合作事宜,预计将在后续推出联合征稿,接收基于Challenge 的研究报告与论文成果。
Leaderboard已正式在Codabench上线,携手探索LLMs在结构化数据理解与推理上的新边界。

挑战赛链接:https://www.codabench.org/competitions/12019/
任务定义与主要发现
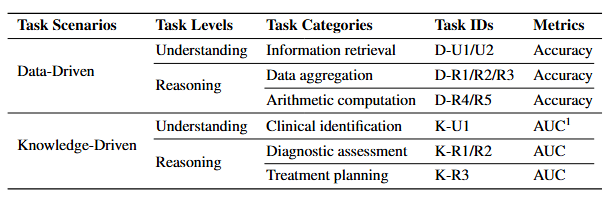
基于这一任务体系,该文章对多种大型语言模型进行了系统性评估,其主要发现如下。
通用大模型优于医学专用模型:在结构化EHR任务上,通用LLM整体表现明显优于医学领域模型,其中闭源商业模型(特别是 Gemini 系列)取得了最佳结果。
LLM在数据驱动类任务上表现更强:相较于依赖医学知识的任务,LLM在数据驱动型任务上的表现更为稳定和优秀。
输入格式显著影响模型性能:自然语言描述更有利于数据驱动的推理任务,而图结构表示更适用于数据驱动的理解任务;对于知识驱动类任务,尚无输入格式能带来稳定提升。
Few-shot 能提升性能:少样本示例能够总体提升LLM表现,其中1-shot和3-shot设置通常优于5-shot。
多任务微调优于单任务微调:虽然两者均能提升模型能力,但多任务微调带来的性能增益更为显著
增强方法具有情境依赖性:非医疗领域的增强方法在知识驱动任务上表现不佳,而医疗专用方法在数据驱动任务中同样存在局限。
EHRStruct的总体设计与构建
EHRStruct的构建过程包括四个主要阶段:任务合成、任务体系构建、任务样本抽取与评测流程搭建。该流程由医学专家与计算机研究人员共同协作完成,从临床需求出发,逐步形成一套覆盖多类场景与多层认知复杂度的结构化EHR评测体系。
四个阶段相互衔接:从定义临床相关任务,到构建系统化的任务分类,再到从医疗数据中抽取任务特定样本,最终形成可复现、可扩展的评测流水线,用于系统评估大型语言模型在结构化EHR任务中的理解与推理能力。
任务合成
任务的初始设定由计算机研究人员基于既有研究与常见建模范式进行任务提炼,随后由医学专家审核并确认其临床相关性。
其余四类任务:信息检索、数据聚合、算术计算和诊断评估,则来自结构化EHR中最常见的LLM推理模式。六类任务共同覆盖了多种真实临床需求,兼具操作性与决策支持价值。
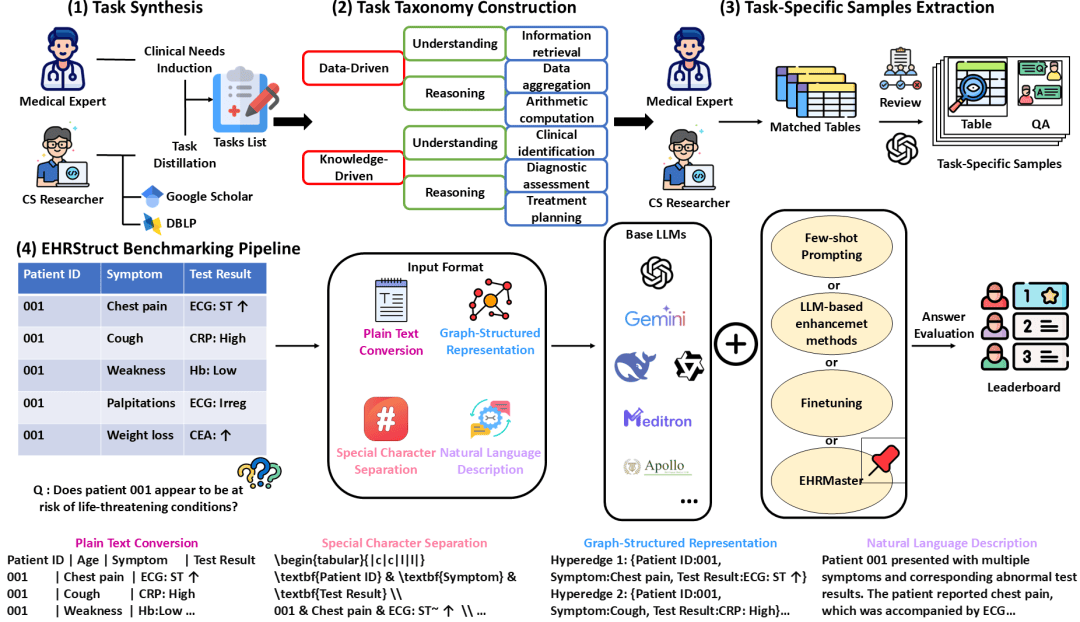
EHRStruct的整体框架概览
任务体系构建
该文章将全部任务沿三条轴线进行组织:临床场景(数据驱动 vs 知识驱动)、认知层级(理解 vs 推理)以及功能类别(六类任务类型)。该分类体系同时体现任务的实际临床意图与推理复杂度,使得评测框架既全面又具可解释性。
任务样本抽取
任务样本抽取阶段为每个任务和每个数据集构建评测样本,EHRStruct基于两个互补的数据源构建评测样本:
Synthea提供高保真、无隐私限制的合成结构化病历,适用于任务定义与可控场景下的样本生成;
eICU Collaborative Research Database则涵盖多机构ICU环境下的真实结构化表格,包括生命体征、检验结果、诊断与治疗过程等,为模型在真实临床条件下的表现提供验证。对于11项任务共生成2,200条带标注样本。
每个样本选取具有代表性的临床数据以确保病例多样性,并基于任务定义、表结构与采样内容,由GPT-4o生成相应的问答对。
评测流程
EHRStruct 为结构化电子病历任务的系统评测建立了一套统一的实验流程。基准涵盖20个大型语言模型,包括通用模型与医学领域模型。
对于每个任务,EHRStruct采用200份问答样本进行评测。所有样本均用四种典型的格式转换方法进行转换输入,包括平铺文本、特殊字符分隔表示、图结构表示和自然语言描述,并在各数据源中和模型中分别报告不同输入格式的表现。评测均采用单轮生成,并使用统一的超参数以保证模型比较的公平性。
除基准级别的全面评测外,EHRStruct 还支持在特定模型上进行深入实验。例如,可对某一模型系列开展 few-shot 提示与微调实验,以探索其在结构化EHR场景中的潜在性能表现。
此外,基准还复现并比较了11种结构化数据推理方法(包括8种非医疗领域方法与3种临床方法)。
最后,EHRStruct提供了一种全新的方法EHRMaster用于帮助LLM处理结构化医疗任务,并全面比较其优势。
实验结果
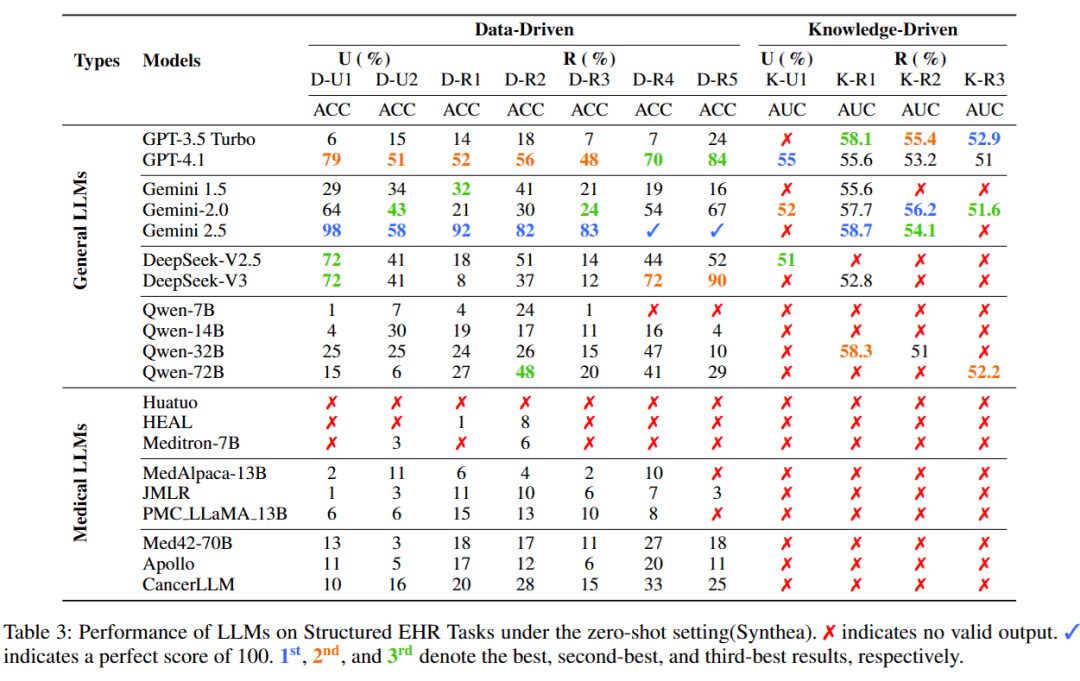
LLM在结构化 EHR 任务上的零样本表现
研究人员测试了各类大型语言模型在Synthea数据集上的零样本表现,结果按照任务情境(数据驱动 (Data-Driven)与知识驱动 (Knowledge-Driven))以及认知层级(理解(U) 与推理 (R) )进行组织。
可以看到,通用大模型在绝大多数任务中明显优于医学专用模型,尤其是在知识驱动类任务上,医学模型往往无法生成有效输出,而通用模型仍能保持稳定表现。
其中,以Gemini系列为代表的闭源商业模型整体排名领先,展现出对结构化EHR任务更强的泛化能力。
此外,不同任务类型之间也呈现明显难度差异:数据驱动类任务表现整体较好,而知识驱动类任务,特别是诊断评估与治疗规划,仍对现有模型构成显著挑战。
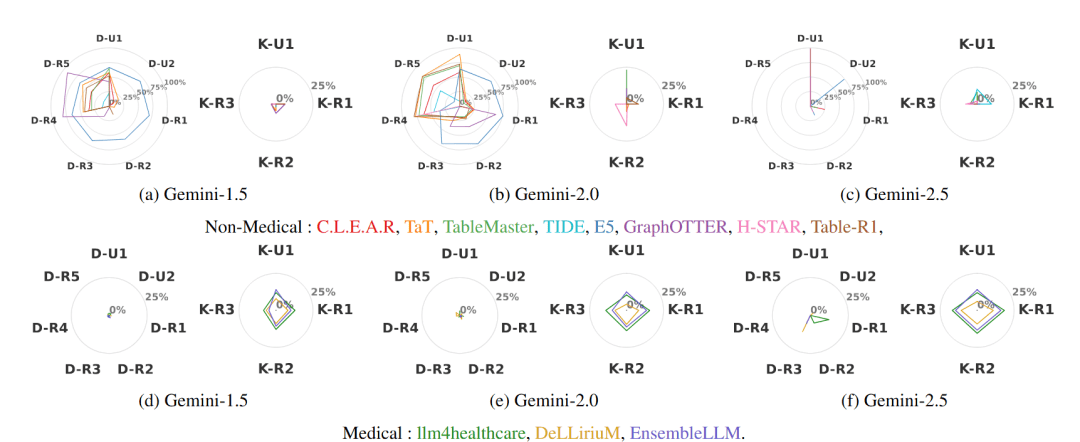
11种SOTA方法的相对增益对比
研究人员复现并评估了11种代表性SOTA方法,涵盖8种通用非医疗模型与3种医疗专用模型,结果揭示了显著的性能割裂:通用方法擅长数据驱动的逻辑与数值推理,但在临床知识任务上表现平平;反之,医疗方法虽精通疾病预测等知识驱动任务,却难以泛化至通用数据场景。
这种现象表明,当前没有任何一种方法能全覆盖EHR任务,领域亟需兼顾结构化逻辑推理与临床知识融合的统一解决方案。
EHRMaster与LLM增强方法的基准性能对比
研究人员提出的EHRMaster搭配Gemini各个系列,在基准测试中表现强劲,不仅能十分有效地改善数据驱动任务(在算术推理等场景下多次达到100%准确率),对具有挑战性的知识驱动任务也有一定幅度的性能提升,充分证明了其在结构化EHR推理中的有效性。
作者信息
论文的第一作者是新加坡南洋理工大学计算与数据科学学院的博士生杨潇。
第二作者兼通讯作者赵雪娇博士在百合卓越联合研究中心(LILY Research Centre)担任瓦伦堡–南洋理工大学校长博士后研究员期间完成的这项工作,目前她任职于阿里巴巴—南大全球数码可持续发展联合实验室(Alibaba-NTU Global e-Sustainability CorpLab, ANGEL)担任研究科学家。
第三作者是新加坡南洋理工大学计算与数据科学学院高级讲师及高级研究员Shen Zhiqi
参考资料:
https://arxiv.org/abs/2511.08206
秒追ASI