
国产芯片也能跑AI视频实时生成了,商汤Seko 2.0揭秘幕后黑科技
机器之心报道
编辑:杨文
自 Sora 2 发布以来,各大科技厂商迎来新一轮视频生成模型「军备竞赛」,纷纷赶在年底前推出更强的迭代版本。
谷歌推出 Veo 3.1,通过首尾帧控制和多图参考解决了以往视频生成「抽卡」随机性太强的问题;Runway 拿出 Gen-4.5,强化了物理模拟和表情动作迁移;快手祭出 Kling 2.6,实现了原生音画同步……
各家都在炫技,但一个更本质的问题却常被忽略:这些模型距离真正的生产力工具,究竟还有多远?
12 月 15 日,商汤科技产品发布周正式开启,第一天就重磅上线了全新的 Seko 2.0 版本,让 AI 短剧创作真正实现「一人剧组」。

比如只需输入一句简单的提示词,它立马就能策划剧本大纲,生成分镜和视频,整个过程相当麻溜。
视频来自 Seko 官网,创作者:小铭AI百宝箱
无论是 1 分半钟的 3D 艺术风格的动画短片:
视频来自 Seko 官网,创作者:噪维 AIGC
还是唇形同步精准的数字人音乐 MV,Seko 2.0 也都能在最短时间内信手拈来。
视频来自 Seko 官网,创作者:AI制片人Webb
作为行业首个创编一体、多剧集生成智能体,Seko 已经服务上百家短剧工作室,大量 AI 短剧成功上线。

用商汤 Seko 创作的《婉心计》登顶抖音 AI 短剧榜第一
而此次 2.0 版本的升级,背后是商汤在视频生成底层技术上的深度突破。从开源推理框架 LightX2V 到产品化落地,再到国产芯片的全面适配,商汤正在构建一条完整的 AI 视频生产链路。
视频生成的「不可能三角」
尽管赛道火热,但当 AI 视频生成模型步入短剧制作等实战场景时,往往会撞上由效率、成本、质量构成的「不可能三角」。
目前即便如 Sora 2 级别的产品,生成 10 秒视频往往需要数分钟乃至十分钟。这种漫长的等待时间,让创作者难以进行快速迭代和实时反馈,严重制约了创作效率,更无法支撑工业化生产。
有数据表明,开源模型生成一段 5s 视频通常超过十分钟,商用闭源模型生成 5s 的视频通常也需 1 至 10 分钟不等。这意味着生成与实时播放之间存在着很长的时间差距,距离真正的「强实时生成」,即生成 5 秒视频所需时间小于 5 秒,还有遥远的距离。
实时性问题的背后,是更为本质的计算成本困境。如果要投入如此高昂的算力成本,任何试图用 AI 大规模生产视频内容的商业计划,都会在财务模型上遭遇滑铁卢。
对于 AI 短剧和漫剧创作而言,这个问题更加尖锐。短剧制作的本质是多剧集、多场景、多分镜的复杂工程,这直接导致了计算量的指数级增长。一个仅 5 秒的视频片段就需要生成接近 10 万 token,而在实际创作流程中,一键生成通常会产生 10 到 20 个分镜,这意味着单次操作的 token 消耗量就达到 100 万到 200 万级别。
按照传统视频生成模型的成本结构,制作一集 10 分钟的 AI 短剧,所需的计算资源和时间成本将达到令人咋舌的地步。没有哪家内容制作公司能够承受每生成一分钟内容就要支付数小时高端 GPU 算力的成本。在这种场景下,效率与成本直接决定了项目的生死。
当行业试图通过降低推理步数、压缩模型参数等方式提升速度、降低成本时,又往往会遭遇生成质量下降的挑战。视频的一致性、动态性、画面清晰度都可能在优化过程中受损,而对于商业应用而言,质量是不可妥协的底线。
如此看来,现有的视频生成技术架构似乎陷入了一个「不可能三角」,要么牺牲质量换取速度,要么保证质量但付出巨大的时间和算力代价,要么在两者之间艰难平衡却难以真正满足商业应用需求。这个困局让无数技术团队在实验室里的惊艳演示,最终折戟于真实商业场景的严苛考验。
打破这个困局,需要的不仅仅是单点技术的突破,更需要从算法、架构到系统工程的全方位创新。
商汤悄悄开源的 AI 视频生成框架
速度快 10 倍
今年上半年,一个名为 LightX2V 的开源项目及其推出的图像和视频生成 4 步蒸馏模型,在 ComfyUI 社区走红,还在 Reddit 上引发热烈讨论。截至目前,该项目上传的模型累计下载量已突破 350 万次。
这个备受瞩目的项目背后的研发团队一度颇为神秘,如今答案揭晓,LightX2V 是由商汤科技与北航联合研发的成果,也是业界首个开源的实时视频生成推理框架。
LightX2V 的核心价值在于真正做到了实时视频生成。
它通过一系列创新技术的组合应用,在消费级显卡上实现了强实时生成,生成 5 秒视频所需时间小于 5 秒,速度达到现在行业主流的数倍甚至十倍以上。
算法创新:实时生成的基础
LightX2V 的性能突破首先源于其深层的算法创新。
商汤原创设计的 Phased DMD 步数蒸馏技术,让视频生成在 4 步推理下就能实现高质量的一致性和动态性。这套技术产出的 Wan2.1、Qwen-Image 等多步模型,登上 HuggingFace 趋势榜前 10,累计下载量超过 358 万次。
传统的分布匹配蒸馏(DMD)方法虽然可以将分数匹配生成模型压缩成高效的多步生成器,但在直接扩展到多步蒸馏时,会面临生成多样性显著降低、训练不稳定以及难以有效处理复杂分布的局限性。
为了解决这些难题,研究者提出了 Phased DMD。这是一个结合了阶段式蒸馏和专家混合思想的多步蒸馏框架,旨在降低学习难度并增强模型能力。

图 1:(a) 多步 DMD、(b) 采用随机梯度截断策略的多步 DMD、(c) Phased DMD 和 (d) 采用 SGTS 的 Phased DMD 的示意图。
Phased DMD 建立在两个核心理念之上:
- 渐进式分布匹配:该方法将信噪比(SNR)范围划分成多个子区间,通过这种划分,模型可以渐进式地将自身精度优化到更高的 SNR 级别,从而更好地捕获复杂分布,并提高训练的稳定性和生成性能。在去噪过程中,低 SNR 阶段聚焦于全局结构,而高 SNR 阶段则关注精细细节。
- 子区间内分数匹配:由于要对齐子区间的分布,研究者通过严格的推导,得到一个具有理论保证的训练目标。这个目标能够正确估计子区间内的分数,确保阶段式训练的理论正确性。
Phased DMD 的结构设计是一个天然的 Mixture-of-Experts 架构,允许模型中的不同专家专门学习处理不同的 SNR 阶段,而不会引入额外的推理成本。Phased DMD 不仅原生支持 MoE 模型,而且对于非 MoE 的教师模型,该技术也可以将之蒸馏为 MoE 学生模型。
实验结果表明,Phased DMD 相较于传统 DMD 方法,能更好地保持基模型的动态效果和多样性。Phased DMD 通过蒸馏 Qwen-Image (20B 参数) 和 Wan2.2 (28B 参数) 等先进的模型得到了充分验证,开源的部分模型也受到开源社区的讨论和好评。

来自 Wan2.1-T2V-14B 基础模型(40 步、CFG=4)及其蒸馏变体(4 步、CFG=1)的样本(随机种子 0–3):(a) 基础模型,(b) DMD,(c) 带 SGTS 的 DMD,(d) Phased DMD。与基础模型和 Phased DMD 相比,DMD 与 SGTS 展现出更弱的运动动态。类似地,带 SGTS 的 DMD 倾向于生成特写视角,而 Phased DMD 和基础模型更好地遵循提示中的相机指令。

通过 Phased DMD 蒸馏生成的 Qwen-Image 示例。
在高效视频生成领域,自编码器(VAE)模型是不可或缺的关键组件。它负责将像素空间压缩到更小的潜在空间,以实现更快处理。然而,传统的官方 VAE 模型往往内存占用大、推理速度慢,严重制约了视频生成效率。
针对这一行业痛点,LightX2V 团队发布了 LightVAE、LightTAE 系列高效视频自编码器模型集合,旨在通过深度优化和蒸馏技术,在最大限度保持高清画质的同时,实现高达 10 倍以上的性能提升,为实时生成奠定了坚实的算法基础。
LightVAE 系列被定位为「最佳平衡解决方案」,通过对官方 VAE 架构进行剪枝和蒸馏,例如对 Wan2.1 VAE 剪枝 75%,成功将显存占用减少了约 50%(降至约 4-5 GB),同时将推理速度提升了 2 到 3 倍。LightVAE 保持了接近官方模型的优异质量,使其成为日常生产和高性能需求的理想选择。
对于追求极致速度和最小内存占用的场景,团队则推出了 LightTAE 系列,采用更轻量级的 2D 卷积架构,将显存占用降至极低的约 0.4 GB,并实现了极快的推理速度。尽管其基础架构与开源的 TAE 相似,但 LightTAE 经过团队的蒸馏优化,其生成质量显著超越了普通的开源 TAE,达到了接近官方 VAE 的水平,非常适合开发测试和快速迭代等对效率有高要求的场景。
实际测试结果表明,LightX2V 的优化效果是显著的。例如,在处理一段 5 秒 81 帧的视频时,官方 Wan2.1 VAE 的解码时间约为 5.46 秒,显存需求超过 10 GB。相比之下,LightVAE 将解码时间缩短到约 2.07 秒,显存降至 5.57 GB 左右。而 LightTAE 则表现出惊人的速度,解码时间仅需约 0.25 秒,且显存几乎可以忽略不计。

工程创新:全栈优化实现「强实时」
真正让实时生成视频变为可能的,是 LightX2V 在工程层面的全栈优化。
LightX2V 构建了一个面向低成本、强实时的视频生成推理完整方案,覆盖了模型、调度、计算、存储和通信五个维度,通过低比特量化、稀疏注意力、特征缓存、高效 Offloading 和多卡通信优化等技术,形成了清晰且高效的五层体系结构。

在框架的最底层是算子实现层,它是所有性能优化的根基,集成了多种高度定制和优化的低级计算操作,特别是针对计算密集型的注意力机制。通过引入 Flash Attention V3、Sage Attention V1/V2/V3、Radial Attention 和 Ring Attention 等创新算子,LightX2V 为上层提供了强大的计算加速能力,从硬件层面保证了推理的高效运行。

紧接着是内核库层,它负责封装底层算子的复杂性,并为上层模型提供稳定、高性能的调用接口和运行时环境。
再向上,框架的核心执行环境位于模型模块层。该层以并行推理为核心机制,最大化了计算资源的利用。它包含一个负责任务顺序和时间步管理的调度器,以及一个支持主流视频生成模型如 Hunyuan、Cogvideo 和 Wan 系列的模型组件,还集成了 Offload(用于显存卸载管理)和 Weight(权重管理)等模块,确保了在有限硬件资源下依然能够高效运行大型模型。
在模型模块之上,是 LightX2V 的优化算法层,这一层汇聚了框架的关键加速策略。它通过量化技术来压缩模型体积并加速计算;利用特征缓存来避免中间结果的重复计算;并结合底层的优化算子实现高效注意力机制,共同将模型的推理效率推向极致。
最后,位于顶层的是用户入口层,它体现了 LightX2V 的易用性。为适应不同场景,框架提供了多样化的接入方式,包括集成到流行的节点式工具 ComfyUI Workflow 中、通过 Gradio Web 快速部署在线演示服务、支持本地服务器部署,以及提供用于稳定生产环境的静态推理接口。
这种全栈优化带来的直接效果就是显存门槛降至 8GB 以下,入门级消费卡即可流畅运行;在 RTX 5090 等消费级显卡上,已经实现了 1:1 的实时生成效果。
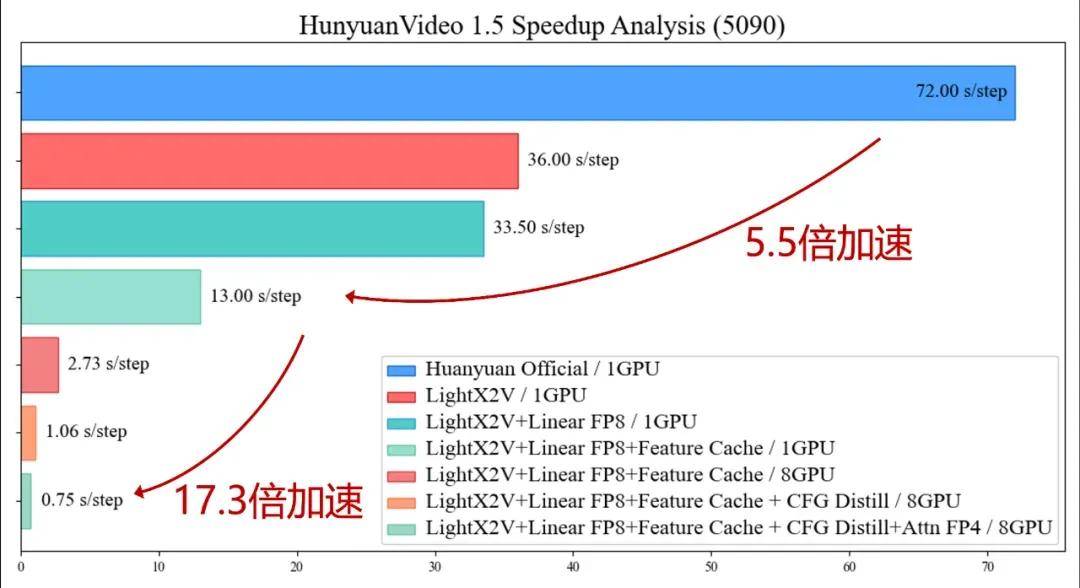
从技术架构来看,不是简单优化某个环节,而是构建了一套面向低成本、强实时的视频生成推理完整方案,这也是为什么它能在开源社区获得如此广泛关注的原因。它不仅是一个模型,更是一个可落地、可复用的技术框架。
国产化芯片适配
商业化的最后一块拼图
技术突破之外,商汤在 Seko 2.0 中还实现了另一个关键布局 —— 全面适配国产化芯片。
借助 LightX2V 框架,Seko 已成功支持多款国产 AI 芯片,真正实现了视频生成模型的全国产化部署能力。
从实际效果来看,在国产芯片与英伟达芯片上生成的视频,质量差距并不明显。虽然国产芯片的生成速度略慢,但其性价比优势突出。未来商汤计划给创作者提供国产化和非国产化两套方案,使用国产化方案的用户将获得更优惠的价格政策。
英伟达芯片(左)和国产芯片(右)生成视频对比
这不仅仅是成本优化的技术选择,更是对国产 AI 生态的战略性支持。在视频生成这一 AI 应用的关键场景中,打通从算法框架到硬件芯片的全链路国产化能力,意味着中国 AI 产业在核心技术上迈出了实质性的一步。
当视频生成真正做到实时、低成本、可规模化,AI 短剧乃至更广泛的视频内容创作,或许将迎来真正的生产力革命。而这场革命的起点,正是像 LightX2V 这样从底层技术开始的系统性创新。
文中视频链接:https://mp.weixin.qq.com/s/JkH_x_aajxyzG8_EzLQ8Tw