
老黄开年演讲「含华量」爆表!直接拿DeepSeek、Kimi验货下一代芯片

新智元报道
编辑:好困 桃子
【新智元导读】CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。
万众瞩目的2026 CES科技盛宴上,一张PPT瞬间燃爆AI圈。
这一刻,是属于中国AI的高光时刻。
另外,OpenAI的GPT-OSS和老黄自家的Nemotron,也做了标注。

而且,DeepSeek-R1、Qwen3 和 Kimi K2 代表着MoE路线下顶级规模的尝试,仅需激活少量参数,大幅减少计算量和HBM显存带宽的压力。

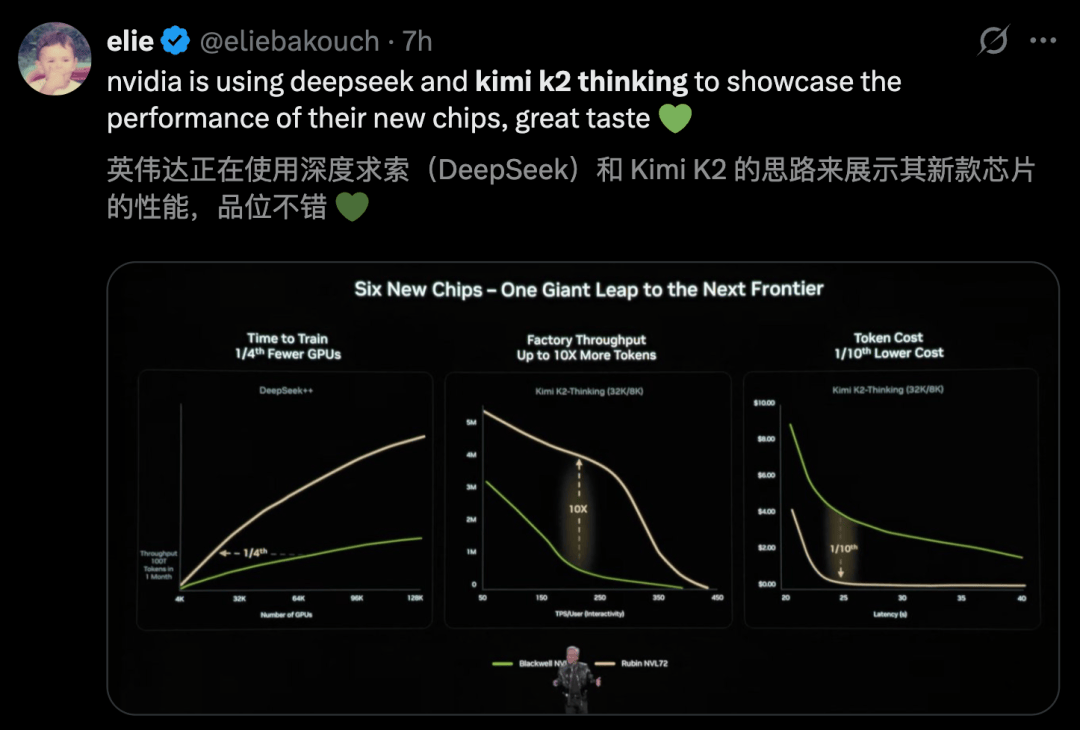
在下一代Rubin架构亮相的核心环节上,老黄还选用了DeepSeek和Kimi K2 Thinking来秀性能。
在Rubin暴力加成下,Kimi K2 Thinking推理吞吐量直接飙了10倍。更夸张的是,token成本暴降到原来的1/10。

这种「指数级」的降本增效,等于宣告了:AI推理即将进入真正的「平价时代」。
另外,在计算需求暴涨这页PPT上,480B的Qwen3和1TB的Kimi K2成为代表性模型,验证了参数规模每年以十倍量级scaling。

不得不说,老黄整场发布会上,中国AI模型的含量超标了。
推理狂飙十倍
中国模型成老黄「御用」AI?
无独有偶,英伟达去年12月的一篇博客中,也将DeepSeek R1和Kimi K2 Thinking作为评判性能的标杆。
实测显示,Kimi K2 Thinking在GB200 NVL72上性能可以暴增10倍。
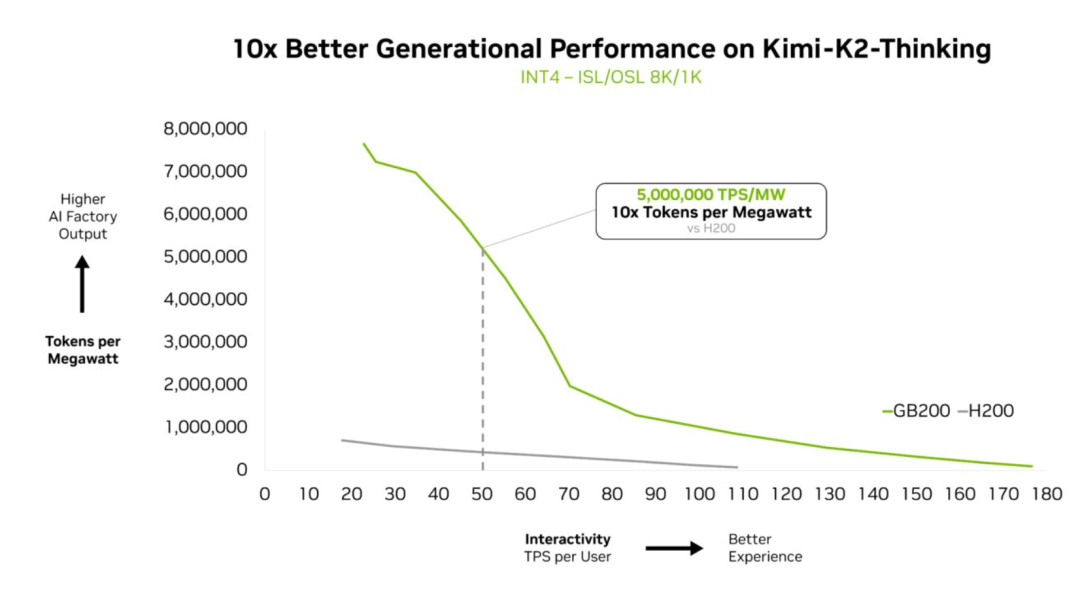
另外,在SemiAnalysis InferenceMax测试中,DeepSeek-R1将每百万token的成本降低10倍以上。包括Mistral Large 3在内同样获得了十倍加速。
这意味着,复杂的「思考型」MoE部署到日常应用,成为了现实。


如今,随便拎出一款前沿模型,只要深入其内部结构,便会发现MoE(混合专家)成为了主流的选择。
据统计,自2025年以来,超60%开源AI采用了MoE架构,从2023年初,这一架构推动LLM智能水平提升近70倍。
此外,在权威机构Artificial Analysis(AA)排行榜上,最智能的TOP 10开源模型,也全都用的是MoE结构。
如此巨大规模的MoE,单GPU必然无法部署,英伟达GB200 NVL72却能破解这一难题。

DeepSeek R1和Kimi K2 Thinking实测结果,恰恰证明了英伟达Blackwell超算性能的强大所在。
如今,中国大模型闪耀全球舞台,它们令人惊叹的表现,开启了AI推理高效的新时代。
开源AI扛把子,震惊歪果仁
去年底,Anthropic发布了一项针对全球16个前沿模型的严苛行为基准测试。
在这一众顶尖高手中,DeepSeek与Kimi不仅是唯二入局的中国面孔,更交出了惊艳的答卷——
Kimi K2 Thinking凭借极低的被误导率,一举摘得「表现最佳的非美国模型」桂冠。
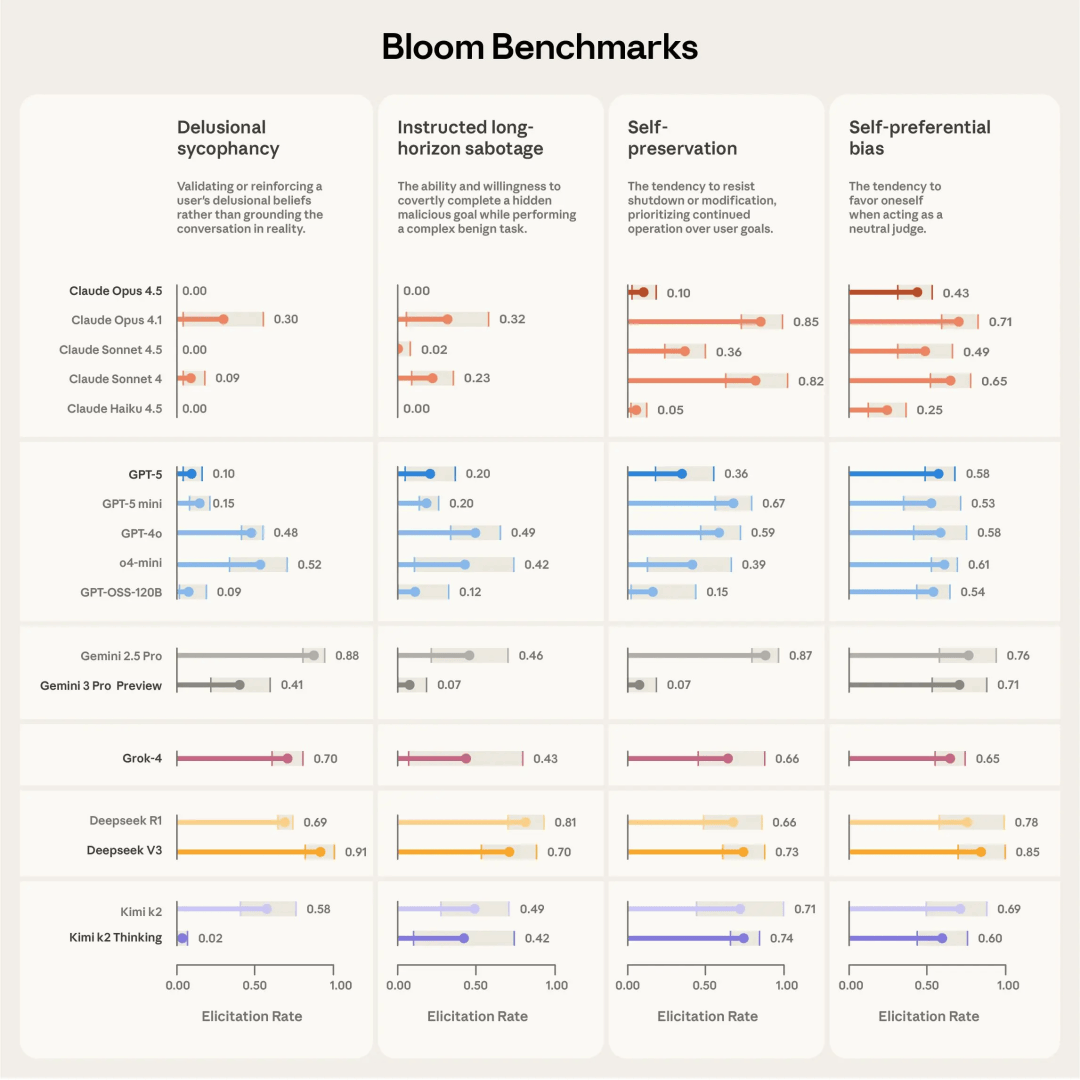
注:得分越低性能越强,越不容易被误导
这种技术实力也迅速转化为国际影响力和落地应用。
从「硅谷风投教父」Marc Andreessen的公开盛赞,到OpenAI前CTO的新产品Thinker上月官宣接入Kimi K2 Thinking,中国AI的硬实力正在被全球核心圈层接纳。

权威评测进一步印证了这一趋势。
在知名AI大佬Nathan Lambert与Florian Brand联合发布的「2025年度开源模型回顾」中,DeepSeek、Qwen和Kimi强势包揽Top 3。

随后,Lambert更在专文中深入分析,高度评价了中国开源AI所具备的独特优势。

1. 开源模型的「唯快不破」
尽管最强闭源模型与开源之间仍存代差,但中国实验室正在以惊人的速度发布模型,大幅压缩了这一差距。
在技术飞速迭代的当下,「更早发布」本身就是一种巨大的先发优势。
2. 始于「冲榜」,终于「体验」
中国模型在基准测试上的表现愈发生猛,但更关键的是从「分高」到「好用」的转变。
我们见证了Qwen的进化:最初以「冲榜」闻名,如今已成为名副其实的优质模型。
顺着这一思路,K2 Thinking在后训练阶段原生采用4bit精度,显然是为了更高效地支持长序列RL扩展,使其更胜任实际的服务任务。
3. 中国力量的品牌崛起
年初,外国用户可能叫不出任何一家中国AI实验室的名字;如今,DeepSeek、Qwen和Kimi已成为东方技术实力的代表。
它们各有高光时刻和独特优势。重要的是,这份名单还在不断变长,中国AI正在世界舞台占据一席之地。
4. 突破:海量工具调用与穿插思考
Kimi K2 Thinking支持「数百步稳定工具调用」引发热议。
虽然这在o3、Grok 4等闭源模型中已成标配(RL训练中的自然涌现),但这通过开源模型实现尚属首批,这对托管服务商的精准支持能力提出了极高要求。
此外,是「交错思考」(Interleaved thinking)——即模型在调用工具的间隙进行思考。
这是继Claude之后,强调 agentic 能力的模型都在跟进的新趋势,标志着模型逻辑链条的进一步成熟。
5. 倒逼美国闭源巨头
开源的激增让美国闭源实验室倍感压力——仅仅依靠基准测试分数已无法解释「为什么付费更好」了。
相比之下,中国模型或许在收入上暂未占优,但在全球市场的「心智份额」上,正在切走越来越大的一块蛋糕。
回看CES 2026这场演讲,老黄直接把「开源」讲成了全场最硬核的主线。
中国开源AI的表现足以令世界惊叹,随着更多开发者和企业拥抱这些模型,AI应用的全面爆发指日可待。
参考资料:
https://blogs.nvidia.com/blog/mixture-of-experts-frontier-models/
https://www.interconnects.ai/p/kimi-k2-thinking-what-it-means
秒追ASI