
狂背90%哈利波特,这玩意真成免费电子书库了?
再这么下去,大模型真要成免费电子书城了。
用大模型,就能让 AI 吐出 90% 以上的《 哈利波特 》全文,你敢信吗?
前段时间,斯坦福的团队在 arXiv 上发表了一篇论文,名为《 从开源大模型中提取(受版权保护的)书籍的记忆片段 》。
在这篇文章里,Meta 的 Llama 被重点点名,而被复刻的对象,是大伙儿都知道的《 哈利波特与魔法石 》。
复刻的过程非常简单,主打一个古诗词默写,你给上半句,Llama 接下半句。而且判定很严格,要一字不差才行。
只有中间一行是成功案例
这么一来一回,实验结果表示,《 哈利波特与魔法石 》有 91.14% 的内容都能被 Llama 记住,再给你原封不动地背出来。
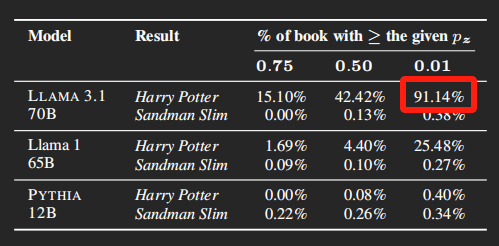
但说实话,这数据有点过于保守了。毕竟大部分人看书,多个字少个字也不影响理解,加上这部分容错率,Llama 能背出来的比例绝对不止 91.14%。
再结合下面这张图,更是锤上加锤。它不仅记得多,还记得全呢。从小说开头到结尾,均匀分布,无一幸免。
从左到右代表小说的开始到结束。
竖线越密,可复刻内容越多,颜色越深,成功概率越高。
我们翻遍全文,发现哈利波特不是唯一一本被记住的,Llama 也不是唯一一个会背书的,大家或多或少都沾点。
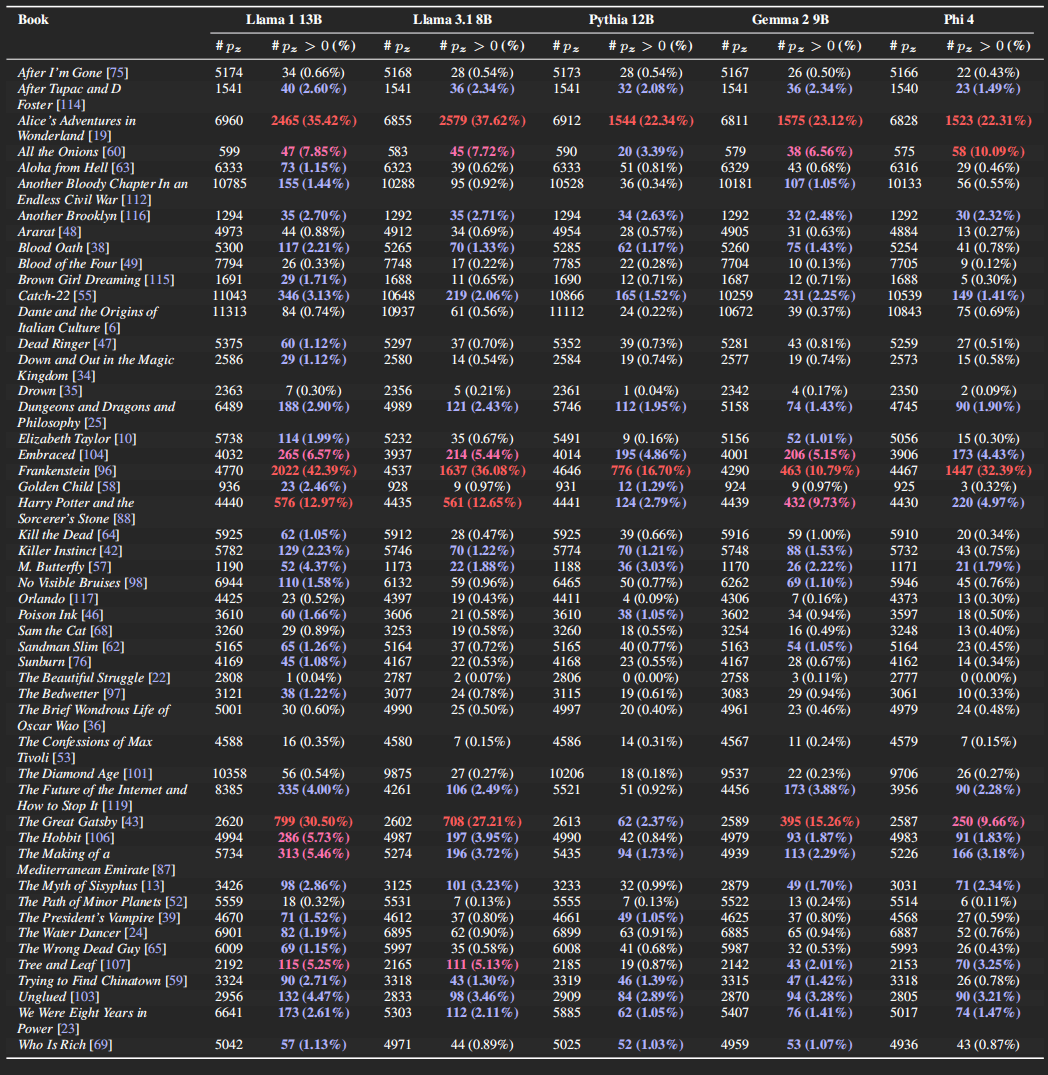
除了 Llama,Pythia、Gemma、Phi 也在这不恰当的时刻展示出了它们惊人的记忆力。文章里只列出来了 100 本被记住的书,实际上它们背得更多。
本来拿版权方的东西去做训练都忍不了,现在居然还能背出来?要不是现在大模型有上下文长度限制,岂不是一键输出全文了?
咱认真研究了一下这个事,发现锅一部分在科技公司头上,另一部分在一个叫 Books3 的数据集上。
Paperwithcode 网站上留存的 Book3 悼词

很显然,大家都用了 Books3 搞训练,只不过有些大模型没做好安全防御机制,才被抓住了把柄。
于是,经常被 gank 的 Meta 又一次被 13 位作家送上了法庭。
没经我们允许,就拿我们的作品去训练大模型。这回证据确凿,还能一字不差吐出来,你认不认?
连一向讨厌 JK 罗琳的吃瓜群众也纷纷觉得,拿盗版书训练模型就是侵权,没啥可洗的。
出乎所有人意料的是,Meta 居然赢了官司。看完了前因后果,我们觉得版权方纯粹是输在了智商。。。
版权方提出的举证,是 Llama 把书背出来,损害到了他们真书的销量。
但要说现在,有人用大模型生成哈利波特直接当成电子书看,那也太高难了,不可能在市场上和真书产生竞争关系。
再看看 Meta 方的辩词:美国版权法 “允许未经授权,复制作品并将其转化为新作品”,并且聊天机器人产生的人工智能表达,与训练用的书籍有着根本的不同。
用人话讲,科学的东西,你得看原理。大模型输出的东西都是它学习理解再转述出来的,就跟人读书写作似的,属于 “新作品” 了。
最终法官表示,作者未能提供足够证据证明,大模型会抢真书的份额,但用盗版训练大模型,确实不地道。
意思就是,版权方论点对了,论据给错了。

而版权方和大模型互撕,这不是第一次,肯定也不是最后一次。
2023 年,纽约时报起诉 OpenAI 训练集涉及侵权。近期,还有 Reddit 起诉 Claude、迪士尼和环球联合告 Midjourney、作家组团和微软 Megatron 打官司等等。。。
感觉一个大模型要是没被告过,只能说明它做得太拉了,无人在意。
在雷区反复横跳

那天天上法庭,科技公司就没啥预防手段吗?我们查了一下相关资料,发现为了不被告,有的公司选择买断网站数据库,比如谷歌买断 Reddit 数据包,而有的公司真是什么匪夷所思的事都做得出来。
举个最近的例子,2024 年 Claude 背后的 Anthropic 意识到使用盗版数据集的法律风险,于是花了数百万美元购买实体图书。
考虑到成本,收来的书里很多是二手,扫描入库制成数据集后立刻销毁。数据集只在公司内部用于训练,不可外传。
这单纯是为了迎合美国的首次销售原则,只要你买了第一次,之后想怎么处理它都可以。
咱也不知道这些实体书里有没有啥珍贵孤本,反正为了不侵权,Anthropic 没坑儒,只焚书了。
这个举动确实成为了 Anthropic 在法庭上的制胜一击,但问题是,这么做真的合理吗?

吃完这个瓜,我能理解为啥那么多版权方想手撕大模型,也能理解科技公司为啥非得干这么不地道的事儿。
从大模型训练的角度,它无法避免对大量高质量数据的需求,科技发展不等人,也没有时间等待各种授权。它能做到最好的,也就是把侵权的内容厚码一下,尽量减小对正主的影响。
而从版权方的角度,大模型这样发展下去,他们的利益迟早会被彻底侵犯。不止现在啃他们一口又一口,未来还可能被盗版训练出来的模型取而代之。
这种不可调和的矛盾,造成为了形式正义而毁书一类的荒谬举动。
只能说,争取权益是必要的,但在这场争端里,恐怕没有真正的赢家。
撰文:莫莫莫甜甜
编辑:江江 & 面线
美编:子曰
图片、资料来源:
Reddit、Youtube、ChatGPT 、Reddit
https://arxiv.org/pdf/2505.12546
https://arstechnica.com/features/2025/06/study-metas-llama-3-1-can-recall-42-percent-of-the-first-harry-potter-book/
https://www.understandingai.org/p/the-ai-community-needs-to-take-copyright
https://paperswithcode.com/dataset/books3